Example Data Architecture Framework
Traditional Data Governance Framework Meets Modern Data Pipelines to create Open Data Lakehouses
This strategic framework provides a foundation for building Qlik data models that can directly access your data fabric or open data lakehouse. This approach not only serves traditional enterprise needs from archiving to reporting but also enables AI and ML workloads while maintaining robust data governance and compliance. Including for ESG and GDPR. The framework has stood the test of time, with tools constantly improving to deliver you improved outcomes. And, importantly, moving you from batch to real time data pipeline creation.
Qlik’s Cloud architecture offers many forms of data governance and compliance. Qlik is advanced in being able to apply many and various data access and security models, however you first need to understand the governed data access framework that you wish to adopt. Coupled with both your application life-cycle management and external compute strategy.
Differentia Consulting created this document in 2017 (revised 2022, 2025) as a guide from which you can build your data model incorporating other technologies as appropriate. What is important is to recognise the key significance of each stage. You may need more stages, and possibly fewer, however you should build your data model to plan to incorporate into your design the need to meet the intended use case of each, as identified by various BI and data pipeline strategists since BI and data modelling began.
A Data Framework Designed to Scale Both in Complexity and Volume
We suggest that the chief data officer (CDO) of your organisation gains a full understanding of this model and applies the framework to the data first. It is not uncommon for a large organisation with multi-site deployment to join models together and have various levels within each stage. Complexity and need will determine requirement. We recommend clients keep work instructions for each data source as it is added to the data model as various stakeholders will need to approve the use of data at each stage.
Whilst the framework may appear complex to some, it is actually simplified by purpose, for those adopting Differentia Consulting’s #SmarterBI methodology it has been how the design of many QlikView and now Qlik Sense in Qlik Cloud documents have been built over many years. What is different with Qlik Sense, especially SaaS / Qlik Cloud and with Qlik Talend Cloud is the ability to separate data provision by IT from consumption by the business (Business Analysts). In a way to deliver true segregation of duty. Ability to more easily demonstrate compliance and most certainly enjoy Qlik more, and cater for all data related workloads by everyone.
The Leap from Batch to Streamed Data Pipelines
As a result of the Upsolver acquisition by Qlik in 2025 Qlik Talend Cloud will be able to stream data into Iceberg/Parquet* open data Lakehouses that enables real time access to data and metadata/catalogues; either for Archiving, Analytics or AI use cases. Each stage is detailed below and also aligned to the “Medallion Framework” offered by other providers.
Data Pipelines Adopting Iceberg/Parquet with Low TCO and high ROI
*By avoiding vendor lock-in (Iceberg/Parquet is open-source) you can have the best of integrated data pipelines and analytics solutions for less, using Iceberg / Parquet open data lakehouses. Reduced TCO and increased ROI means your real time pipelines can have what your organisation needs when it comes to Data Governance; a Certified Process, Certified Data and Certified Outputs. Plus, the solution scales to meet the demands of the largest companies in the world.
Qlik Governed Data Access – Example Framework
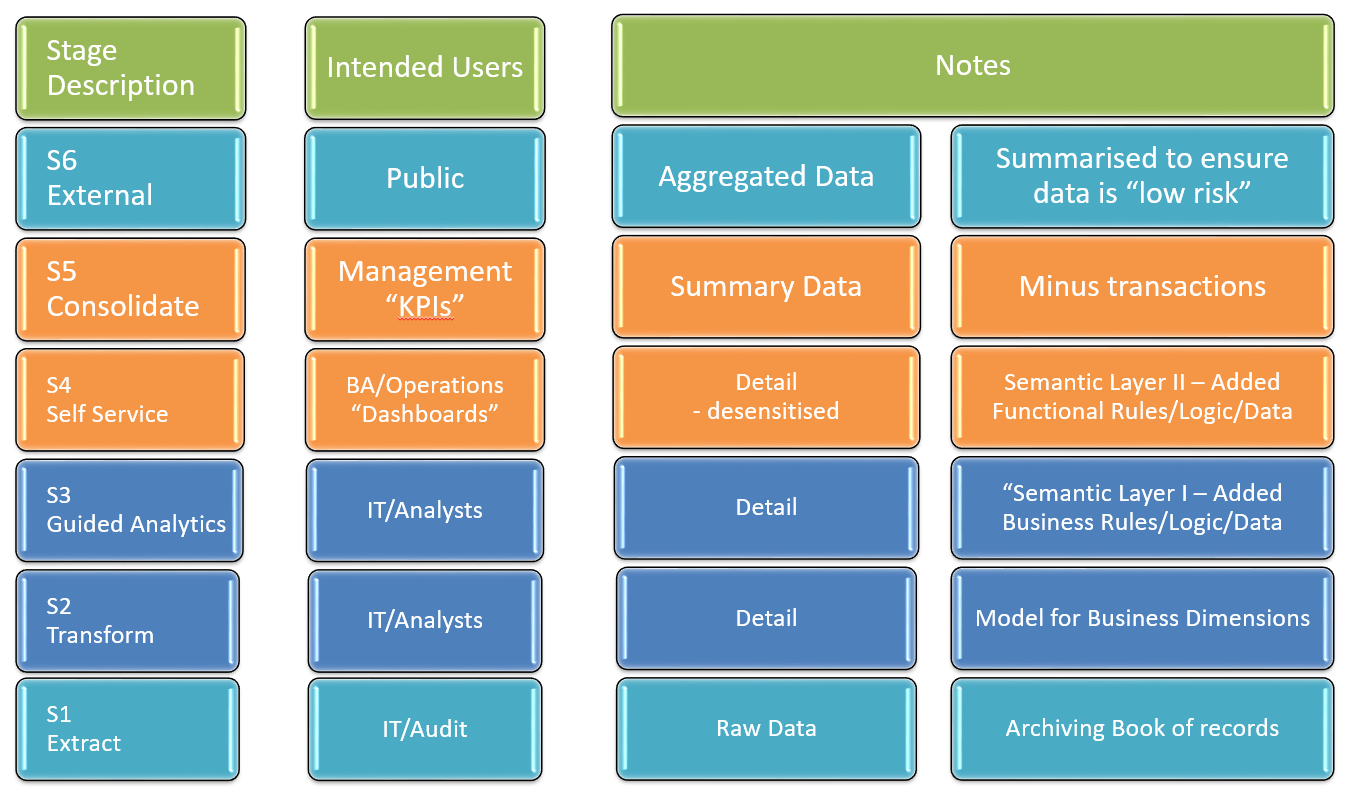
Qlik Governed Data Access, example framework…
To simplify where Qlik’s data pipeline architecture can add value to your enterprise a series of distinct stages, listed in reverse, have been defined to create a framework for data access:
S6 Public – Gold (Refined)
- Analytics-powered public data delivery: Automated Parquet file generation Scheduled public dataset updates Self-service external data sharing
- Desensitised data sets
- External stakeholder access
- API development
- Open data initiatives
- Compliance verification
- Public data catalogues
- AI model serving data preparation
- Data sharing through “Fabric”
Data is desensitised, summarised and aggregated making it low risk and suitable for public consumption to meet the need of external stakeholders.
S5 Consolidated – Gold
- Analytics-driven aggregation: Direct Parquet writing from analytics tools Automated KPI calculations Scheduled metric updates
- Global KPI aggregation in gold tables
- Cross-functional metrics
- Executive dashboards
- Unified business views
- AI-driven insights integration
- Real-time analytics capability
- Analytics-managed data refresh cycles
- Semantic layer optimisation
Serving C-level executives the purpose of consolidation is to provide Global KPIs. Given the type of device or document that this is usually consumed on there is not much need for full drill down. Although to add more detail is not an issue.
S4 Self Service (Derived/Trusted/Production) – Silver to Gold
- Self-service analytics ETL capabilities: User-driven Parquet file creation Guided analytics transformations Business user-managed data prep
- Pseudonymised sensitive data
- Semantic layer implementation
- Business logic application
- AI/ML Feature Store Integration
- “Oven-ready” data sets for AI training
- Analytics-optimised Parquet files
- Vector embedding storage
- Fabric Data Warehouse integration
Semantic “UI” II – Medium Risk: Platform for business discovery in detailed but desensitised pseudonymised data adhering to business rules and logic of the organisation. The UI data stage that Qlik Sense self service is designed for.
Analytics-Driven ETL Convergence Point
Analytics tools create and manage Parquet files Direct write-back capabilities Transformation logic managed in analytics layer
S3 Guided Analytics (Conform) – Silver
- Analytics tools begin ETL ownership: Direct Parquet file generation from analytics layer Business logic implementation through analytics semantic layer Automated data transformations via analytics scheduling
- Sensitive data handling
- Role-based access control
- Data lineage tracking with Fabric catalogue
- AI feature preparation begins
- Iceberg table partitioning strategy implementation
- Time-series optimisation for ML workloads
Semantic “UI” I – High Risk: Addition of additional dimension tables and application of business rules and logic. Corporate guided analytics, Operational Dashboards can be built with this data where permissions allow it.
The application of group rules and section access ensures that only the groups that need to see sensitive field names can see them..
If personal and sensitive data exists but not needed for their role, then S4 data may need to be adopted for compliance purposes.
S2 Transform (Standardised) – to Silver Layer
- Data type standardisation and schema enforcement
- Column name normalization
- Data quality validation and profiling
- Automated integrity checks
- Implementation of data contracts
- Iceberg table optimization for query performance
- Initial metadata tagging and catalogue integration
The aim is to create a data model with Dimensions that are consistent, initial transformation is simply for the purpose of ensuring that all column names both comply and data at the stage can be used for validation and Quality purposes. Many clients run integrity/quality checks with Qlik and send alerts with Qlik Application Automation, Qlik Reporting Services, ancoreShare or NPrinting. This can be an automated process. Access should be strictly controlled at this stage and processes automated.
S1 Extract (Landed/Raw) – Bronze
- Raw data ingestion from various sources
- Iceberg tables for enhanced metadata management
- Immutable storage in Parquet format
- Version control and time travel capabilities
- CDC (Change Data Capture) implementation
- Initial data quality assessment
Creation of a time stamped record of a file/table at a point in time, “Raw”. (Daily weekly monthly etc.)
Note: The endpoint of this stage would historically be contained in Qlik as QVDs or a data warehouse or data store, such as Snowflake, Databricks e.g. for Archiving purposes, today we advocate an open source Lakehouse approach.
Each stage above is individually expandable to include multiple levels and parallel test/sandbox stages. For an international organisation deploying Qlik locally, and consolidating financials by region with Qlik, then globally there can easily be 6 to 20 levels, the stages will remain the same.
With the advent of Iceberg/Parquet we would look to build data assets that meet the needs of the business. Catalogued, and consumed via compute capability as required.
Analytics and Pipeline Convergence
Highlighting the merger of technologies:
Analytics-Driven ETL Benefits
- Reduced data movement
- Business logic maintenance in one place
- Self-service data preparation
- Direct Parquet file creation
- Automated transformation scheduling
- Unified security model
- Consistent business rules
Key Integration Points
- Stage 3: Initial analytics ETL ownership
- Stage 4: Self-service transformation
- Stage 5: Automated aggregation
- Stage 6: Public data delivery
Technical Implementation
- Analytics tools write directly to Parquet format (Stages 4,5,6, and potentially 3 also)
- Iceberg table management through analytics layer
- Automated refresh cycles
- Direct lake ingestion
- Write-back capabilities
- Transformation logging
- Version control integration Modern Implementation Considerations
- Iceberg Catalogue as the central source of truth (Cross platform / Open source)
- AI-optimized storage patterns
- Vector storage for LLM applications
- Data mesh principles
- Data contracts and governance
- Real-time processing capabilities
- Optimised query performance through Iceberg
AI-Ready Data Architecture
- Feature Store integration at Stage 4
- Vector embedding storage optimisation
- Training data versioning through Iceberg
- Model serving data preparation
- Real-time feature engineering capabilities
- Automated data quality for AI workloads
- Integration with popular ML frameworks
AI enabled #SmarterBI with Qlik
Qlik platform-enabled visual analytics, delivered by products supporting some of the world’s largest and most innovative companies and organisations. In addition to our Smarter.BI methodology Differentia Consulting has built many Smarter.BI applications with Qlik, forming a client specific Smarter.BI platform which delivers secure and GDPR compliant operational intelligence solutions. TCO, ROI and simplicity are the keys to driving adoption of a Smarter.BI platform powered by Qlik’s data pipeline and platform-enabled visual analytics offerings.
Terminology explained
What is an open Data Lakehouse?
An open Data Lakehouse is an open data management architecture, that provides a structured transactional layer over low-cost cloud object storage, enabling fast reporting and analytics directly on the data lake. Where you need the flexibility to handle a high volume of varied unstructured data types and intend to leverage advanced analytics and AI, you’ll be served better by a data lakehouse. Importantly open data lakehouses avoid vendor lock-in and permit cross application and cross platform utilisation of data, servicing AI and Analytics workloads.
What is a Data Warehouse?
A Data Warehouse is a relational database of structured data, that stores integrated data from one or more sources. A traditional data warehouse, if costly, was seen the most appropriate option if you needed structured business intelligence and reporting emphasising data quality and governance.
What is a Data Lake?
A Data Lake is a centralised repository of your data, that can store both structured and unstructured data at any scale, using distributed storage, connected and managed by your Data Fabric.



